
Redis的五大数据类型

Redis的五大数据类型
赵海波Redis的国旗策略以及内存淘汰机制
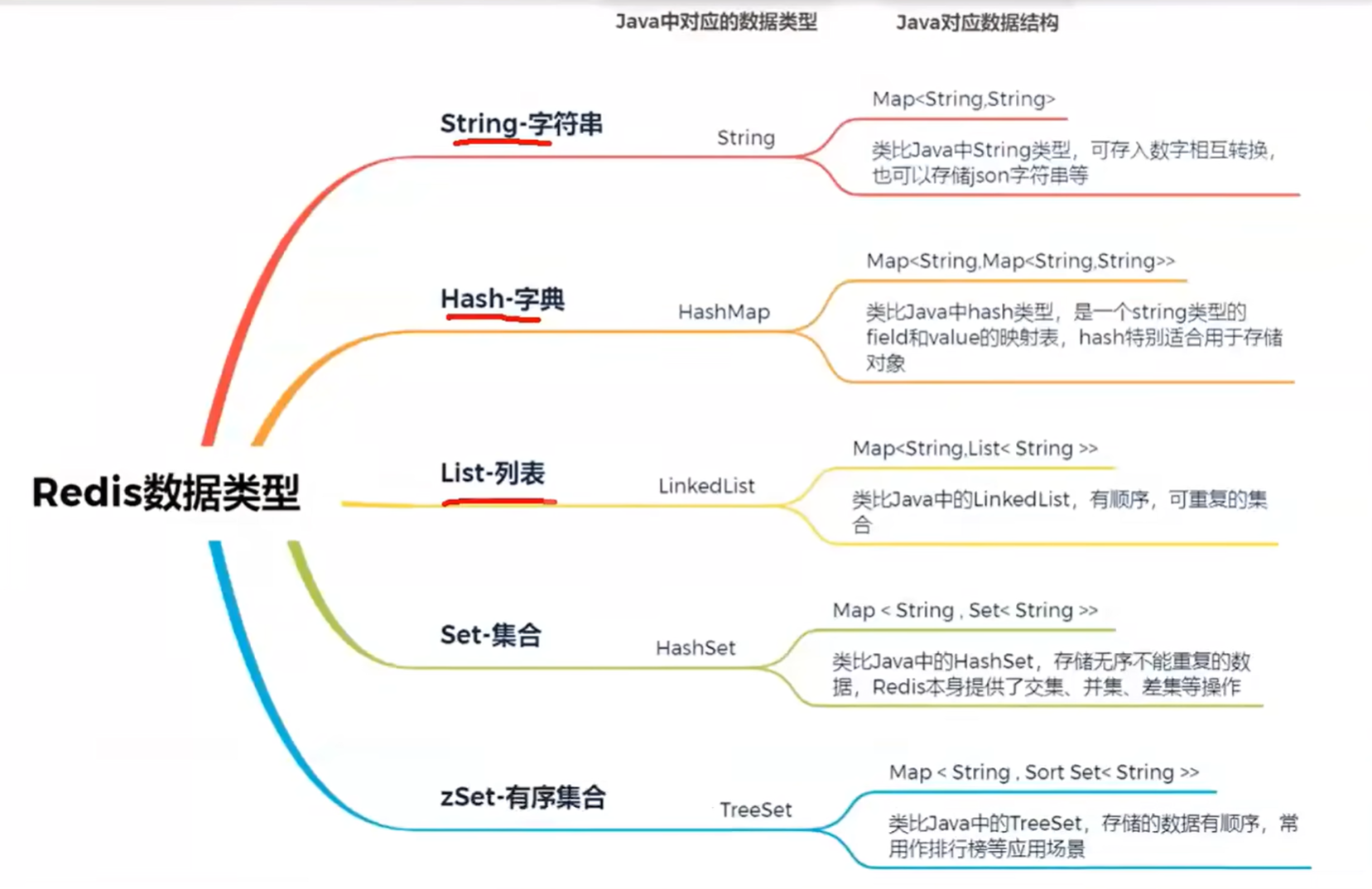
1. String(字符串)
特点:
- 是最基础的数据类型,一个键对应一个字符串值,字符串可以是文本、数字或二进制数据。
- 最大存储容量为 512MB。
常用命令:
SET key value:设置一个键值对。GET key:获取键对应的值。INCR key:对键值进行自增操作。APPEND key value:将值追加到现有的值后面。
使用场景:
- 缓存数据:缓存简单的字符串数据,如用户信息、配置等。
- 计数器:用
INCR和DECR来实现递增或递减的计数功能,如网站点击量统计。 - 分布式锁:可以利用
SETNX和EXPIRE实现分布式锁。
2. Hash(哈希)
特点:
- 适合存储对象的数据结构,一个键对应一个 Hash 表,Hash 表中是字段-值的映射关系。
- 比较节省内存,尤其适用于存储少量字段的数据。
常用命令:
HSET key field value:为 Hash 表的某个字段设置值。HGET key field:获取 Hash 表中特定字段的值。HGETALL key:获取 Hash 表中所有字段和值。
使用场景:
- 存储对象:可以将用户信息、商品信息等以 Hash 形式存储。
- 配置管理:存储和管理较为复杂的配置项,例如用户设置等。
3. List(列表)
特点:
- 一个键对应一个列表,列表是按插入顺序排序的,可以在头部或尾部插入元素。
- 支持双向操作,允许从两端进行数据的插入和获取。
常用命令:
LPUSH key value:将元素插入列表的头部。RPUSH key value:将元素插入列表的尾部。LPOP key:移除并返回列表的头部元素。LRANGE key start stop:获取列表的指定范围内的元素。
使用场景:
- 消息队列:使用
LPUSH和RPOP实现简单的队列模型,如任务调度系统。 - 数据流:如时间轴、用户操作记录等按照时间顺序存储的场景。
4. Set(集合)
特点:
- 一个键对应一个无序集合,集合中的元素是唯一的,不会有重复的成员。
- 提供集合运算,如交集、并集和差集。
常用命令:
SADD key member:向集合中添加一个成员。SREM key member:移除集合中的某个成员。SMEMBERS key:获取集合中的所有成员。SINTER key1 key2:求两个集合的交集。
使用场景:
- 去重场景:如对某些数据进行唯一性检查。
- 标签系统:可以存储用户的兴趣标签或关键词,并通过集合运算来推荐相关内容。
- 共同好友:可以通过
SINTER获取两个用户的共同好友。
5. Sorted Set(有序集合)
特点:
- 类似 Set,但每个元素都会关联一个得分,集合中的元素按得分排序。
- 适合需要排序的数据场景,支持按范围、按得分来获取数据。
常用命令:
ZADD key score member:向有序集合中添加元素及其得分。ZRANGE key start stop:按照得分从低到高获取有序集合中的元素。ZRANGEBYSCORE key min max:获取指定得分范围内的元素。
使用场景:
- 排行榜系统:可以用于实现如游戏排行榜、文章点赞数排名等。
- 延时任务队列:通过将任务的执行时间作为得分,将任务按时间顺序排序。
喜欢这篇文章的人也看了
评论
匿名评论隐私政策



